Designing the Conveyor CI Scheduling Mechanism

A brief introduction on Conveyor CI. Its is a Software framework fdesigned to simplify the development of scalable and reliable CI/CD platforms by eliminating common pain points that a team ight to run into inorder to build a Scalable, reliable CI/CD Platform. It provides a simplified streamlined, developer-friendly development paradigm for building robust custon CI/CD Tools.
Recently a team that uses Conveyor CI as a dependency had an inquiry on how a CI Driver in conveyor can handle multiple instances of running CI processes without overloading the host node. This is a really important consideration I had not thought of, and for a system that runs multiple tasks in concurrency, being conscious of system resources is a really important consideration.
This got me thinking, how best can one approach such an issue. I thought of multiple solutions to this, I had considered introducing a consensus algorithm like raft, however this wasn't really an effective solution. Looking into how the Kubernetes Kube Scheduler efficiently allocates Pods to run on different nodes taking into considerations or the resource constraints of both the Pod to be allocated and the nodes its to be allocated to gave me an inspiration of having to design a custom scheduling algorithm that had to to take into consideration of the multiple, use case scenarios of CI/CD tools and what constraints they operate under.
I had to first come up with the high level requirements and problem statements for the CI Drivers in order to tackle this issue.
The Problem: In large production grade CI/CD Pipelines, multiple requests can initiated at the same time and due to the underlying concurrent and instant execution of CI tasks by Conveyor CI Drivers, this introduces an issue of possible node crashed or driver process termination by the Operating system due to the host node running out of system resources. Also currently, drivers don't support horizontal scalability, something that is really important for CI/CD tools that are expected to run multiple workloads at a certain point in time considering vertical scalability tends to be finite and also costs tend to increase exponentially the more you scale vertically.
From that problem statement I managed to identify two high level requirements.
- Drivers should support horizontal scaling
- The Driver runtime should take into consideration available node resources before executed a task
After a long night of insightful research, I came up with a bunch of solutions for this, these would assist me in designing the scheduling algorithm. I would call the functional or technical requirements if that's the right term to use.
The algorithm was to take inspiration and be a combination of multiple OS scheduling algorithms, with the help of a consensus algorithm to handle and support the distributed properties of the Driver instances.
To solve the issue of the possibility of overloading the server with tasks that require system resources than available, First i had to remove the instant execution of tasks and introduce a task queue, this would enable me to be able to incorporate a FIFO-like architecture as the base algorithm for scheduling tasks in a normal flow. Taking into consideration that in certain organisations, CI/CD tools are designed with the concept of having some tasks prioritized due to multiple factors, say if they would like to prioritize tasks from paying users. I also decided to incorporate a Priority Scheduling Algorithm as the second level algorithm. Lastly, I had to introduce a constraint based scheduling algorithm as the last determining algorithm, these constraints can be the available system resources etc. To support such a complex algorithm, I had to introduce heuristics that are computed by the Driver from a resource specification or defined directly in the resource specification. These heuristics can be task priority, available node resources etc.
On the issue of horizontal scalability, I thought of a consensus algorithm in the driver runtime to ensure a distributed architecture among the Driver instances with also advantages that come with a consensus algorithm like fault tolerance and more. I decided to consider the Raft Consensus Algorithm mainly because of its simplicity and also its proven to work well in the Cloud Native ecosystem with projects like ETCD, Docker, Kubernetes etc using it.
How the Mechanism works
Alright, let's get into how it works. At the core, the tasks are organized in a priority queue, where tasks with a high priority are executed first and in instances where the priority number is equal, they are executed based on a FIFO order based on a timestamp.
Preventing resource contention
Within the tasks Resource specification, I introduced an optional field called resourceUsage that defines the expected resource usage for the task during execution. This acts as heuristic that helps the driver runtime decide whether a certain driver instance is allowed to run the task. It compares the available host node system resources and evaluates whether running that task will not cause resource contention or Out of Memory Errors. This constraint based scheduling considers any node as long as adding the task won't exit 100 percent usage of the resources, that's to say, even if a node is using up to 90% of its resources and adding the task will push it to 99% it will still schedule it on that node. it also tends to prioritize driver instances running on nodes with lower resource usage than the others, say if node A is using 60% and node B is using 55%, it's more likely to consider node B than A. But this will not always be the case, sometimes other factors might cause us to consider node A. Such a mechanism will ensure that the possibility of node failures due to resource contention is really low.
Here is some Pseudo code example to demonstrate the algorithm structure
Initialize priorityQueue ← empty priority queue (higher priority first, FIFO if equal)
Initialize nodeList ← list of available nodes with current resource usage
Function scheduleTasks():
while priorityQueue is not empty:
task ← priorityQueue.dequeue()
eligibleNodes ← []
for each node in nodeList:
if node.canAccommodate(task.resourceUsage):
eligibleNodes.append(node)
if eligibleNodes is empty:
priorityQueue.requeue(task) # Retry later
continue
Sort eligibleNodes by resourceUsage (ascending)
selectedNode ← selectBestNode(eligibleNodes, task)
# Assign task to selectedNode
Update selectedNode.resourceUsage += task.resourceUsage
Function node.canAccommodate(resourceUsage):
return (node.resourceUsage + resourceUsage) ≤ 100%
Function selectBestNode(nodes, task):
# Prefer lower resource usage, but allow for flexibility
# Example heuristic: select node with minimal usage
return nodes[0] # or apply more complex scoring if needed
Function addTaskToQueue(task):
priorityQueue.insert(task) # uses (priority, timestamp) as sort key
Horizontal Scaling
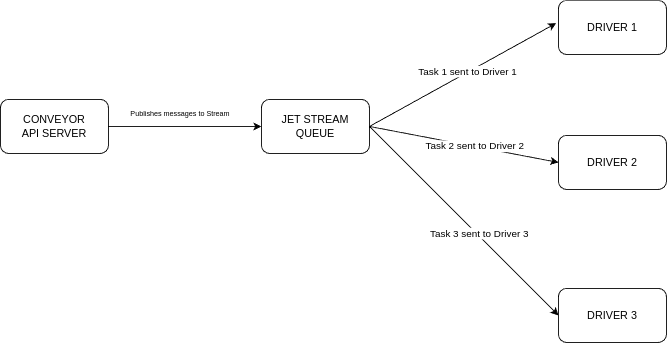
When it comes to horizontal scaling, I decided to re-engineer the Drivers to run as a distributed system in cases where there are multiple driver instances running. This distributed system is powered by NATS JetStream Consumers
At the core each Conveyor CI Driver operates as a JetStream Consumer. They listen to a stream which filters out required messages and pushes them to the driver. The driver then carries out the required tasks depending on the payload recieved from the stream.
The Drivers are configured to use Explicit acknowledgement with the value set to 1 so that each task it handles one by one and this would prevent a possibility of one driver handling multiple tasks at once possibly causing resource contention. Acknowledgement occurs once the message is recieved by the driver. We also set the Delivery policy to All, so that no task is skipped and all tasks are handled. Another feature that Jet
By utilising JetStream, it enables driver to be able to infinitly scale horizontally and become more failt torolent by utilizing various inbuilt NATS features.
Conclusion
Designing a robust scheduling algorithm for Conveyor CI Drivers was a necessary and will definetely improve the functionality and reliability of the Drivers when the scheduling mechanism is added to the Conveyor CI codebase. By combining FIFO, priority-based, and constraint-aware scheduling with a distributed model powered by JetStream, I’ve managed to create a system that not only prevents resource overloads but also opens the door for true horizontal scaling and more features like fault tolorence. This isn’t just a theoretical improvement it directly addresses real-world pain points for teams running concurrent workloads on shared infrastructure. There’s still room to refine and optimize, but this foundation sets the stage for building CI/CD systems that are both resilient and adaptive under pressure. This might be the greatest improvement to Conveyor CI yet.